A Computational Approach
How do we describe a computational process that can extract, analyze and visualize Dickinson's variants?
Expanding the Gothenburg Collation Model
The computational methods applied to extract textual variants in Dickinson’s poems combine the Gothenburg collation model together with an information extraction system. The Gothenburg model has been designed to collate all versions or witnesses of the same text. This model, in its modular structure, facilitates customization of any of the processes to suit the desired goal. For Dickinson’s textual variants, we have modified and customized the model to account for other features of the variants using the feature selection process in the information extraction system. We combine these two models to design what is called ExtractV - a system that is able to process XML transcriptions of poems (texts) with variants. This system can help to index or search for variants across all fascicles and output them for reuse and visualization.
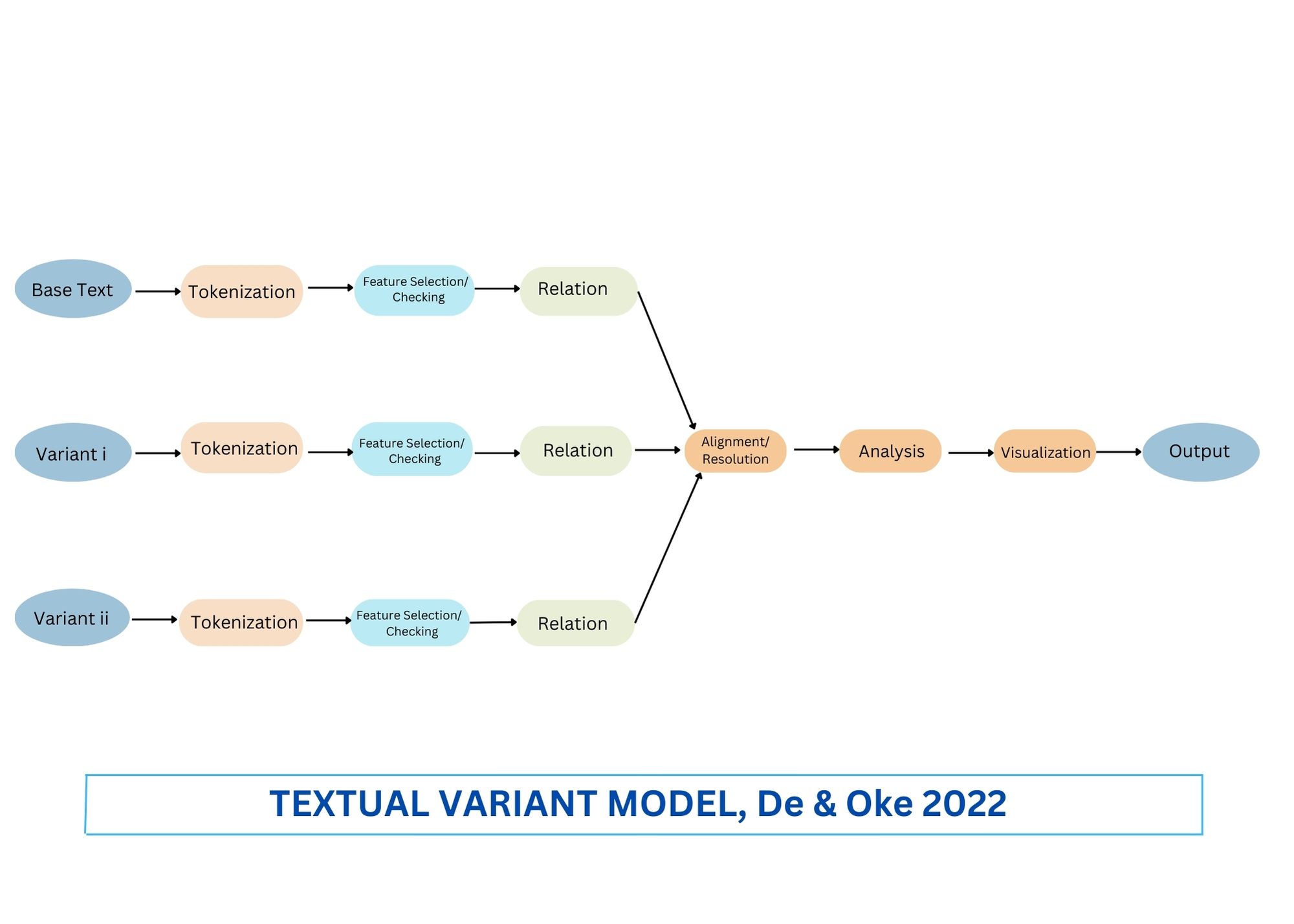
The figure below represents the computational pipeline for extracting variants in text. It begins with the preprocessing stage. Here, we have adopted this stage to show where the data for processing comes from (Franklin). Going by the data, we have two possibilities, namely, the base text and the variant(s). The base text is the word or phrase to which a variant corresponds to. It is in the body of the poem within a sentence through a cross mark (x) or plus sign (+). The variant on the other hand can be a word or group of words usually located at the end of the poem.
The first stage is called Tokenization. Tokenization is typically called a word or stream of characters. It gives input to the Feature Selection or Checking stage. The Feature Selection or Checking stage records the low-level features of words such as part of speech, dictionary match, and regular expression match. The next stage is the Relation. This stage describes the overall syntactic information about every token in the sentence by showing the relationship between words. The goal is to compare the meaning of the base text within the sentence as well as the meaning of the individual variant in the same sentence. The output of the Relation will become the optimal input into Alignment. The Alignment/Resolution stage processes the result of the Relation and determines the forms of variants in use. This will help us to determine the choice Dickinson variants leave the reader with. Whether they are used as alternatives or substitutes in one way or the other. The output of Alignment/Resolution is used as Analysis for the choice or no choice of Dickinson’s variants. This is followed by the Visualization stage which helps to show the distribution of variants across fascicles and to map them into a network of systems. The last stage is the Output. The output represents the results of either the final outcome or any of the stages in the pipeline.
{kind=link}
Introducing the Human Computational Model
Here, I introduce my model for understanding Dickinson textual variants.
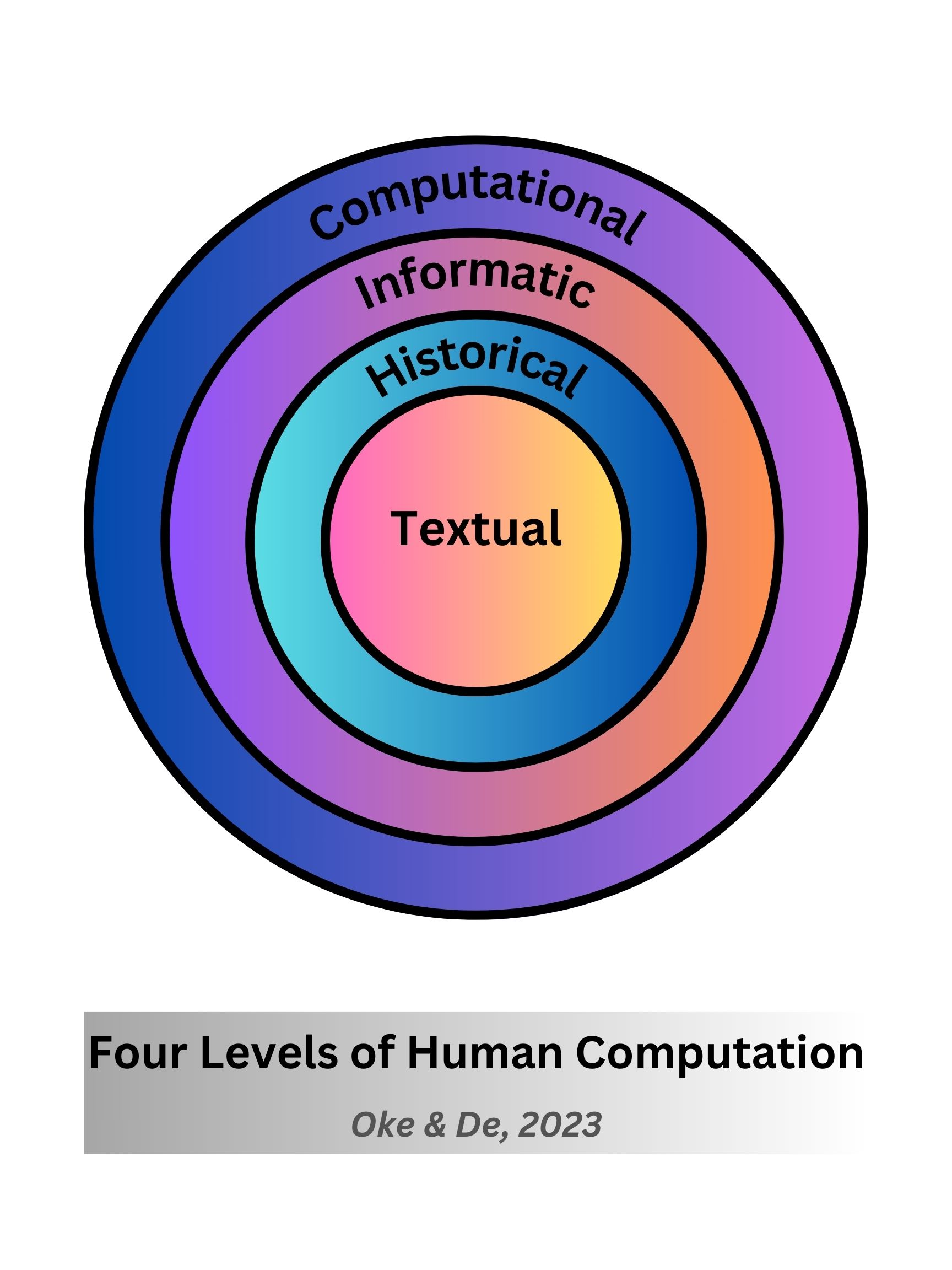
Four levels of human computation:
1. Textual - the materiality of the text (data) with the linguistics
2. Historical - the historical apparatus of the text
3. Informatic - the information about the data, that is, the atomization of data
4. Computational - the discrete states or stages of the information
{kind=link}
Information Extraction System - Natural Language Processing
Using Natural Language Processing technique, especially the information extraction system, we understand that words are processed to show how they're connected with one another in any given context or environment.
This goal is to identify different methods of computing Dickinson’s variants, that is, extracting as well as parsing the variants for easy matching (forms of variants) with the base text. There are two possible ways of approaching this. The first is to extract the data (variants) from the corpus. The other one is to process the extracted variants and check for their matching in terms of meaning with the base texts.
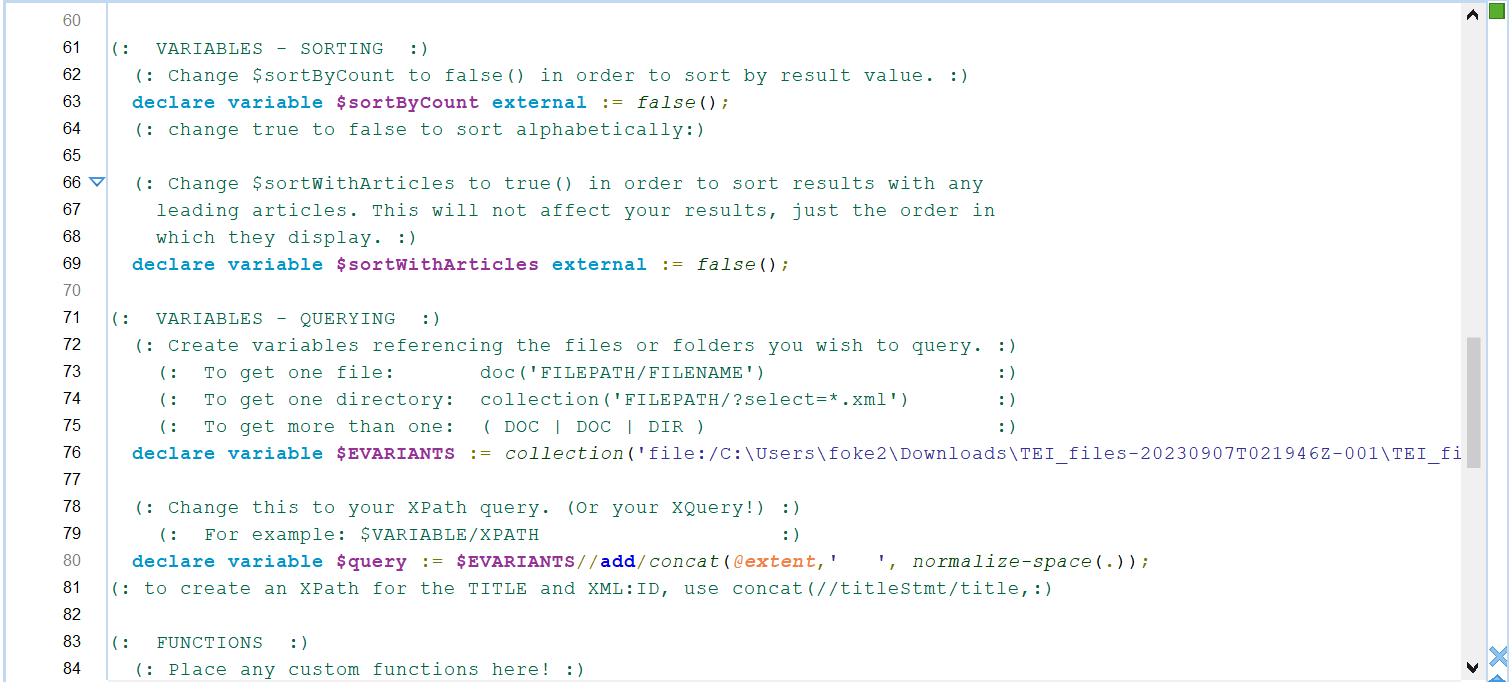
To achieve this level, the XQuery counting robot was used to extract the variants from the XML files and transformed the outputs into whatever csv files. This method helped in generating concordance list for all base texts and variants with the frequencies.
We hope to design a model that will first extract the variants as well as parse the tokens to determine the variant forms. To achieve the first, we use Python, a programming language, to extract tagged variants from the corpus. This is done through writing a code to locate and fetch all words already tagged in the corpus. We expect the output to be parsed into the computational pipeline (the ExtractV model) to generate the part of speech and the meaning using the dictionary in the Python library. These two are identified as text and sentence classifications. With the output of these classifications, we want to compare each variant with the base text to determine their relations.
{kind=link}